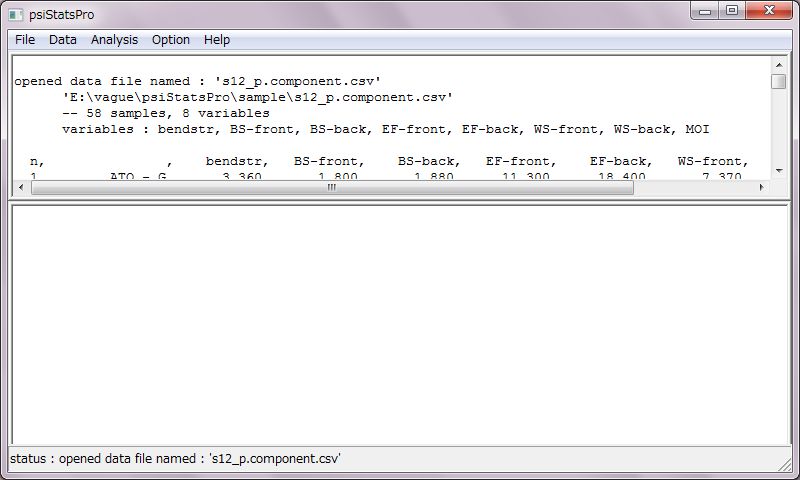
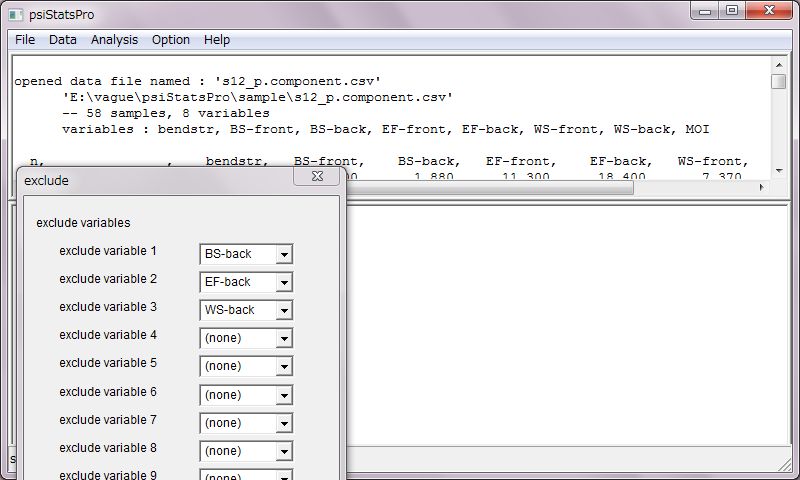
データファイルは、CSVファイル、もしくは、MicrosoftのExcelファイルを用意します。予め、プリファレンスでどちらのファイル形式を使うかを指定しておきます。
Excelファイルの場合は、DDEのみです。ODBCは現在のバージョンでは使えない様にしました。また、DDEにしても使い勝手の良い方法とは思えないので、CSVファイルを使う事を推奨します。
表示の長さは文字数で設定します。変量の名前にも同じ制限が加わります。小数点の位置は自動で最適化されます。もちろん、計算精度とは無関係で、あくまで表示の制限です。また、重要な数値はこの制限を受けません。
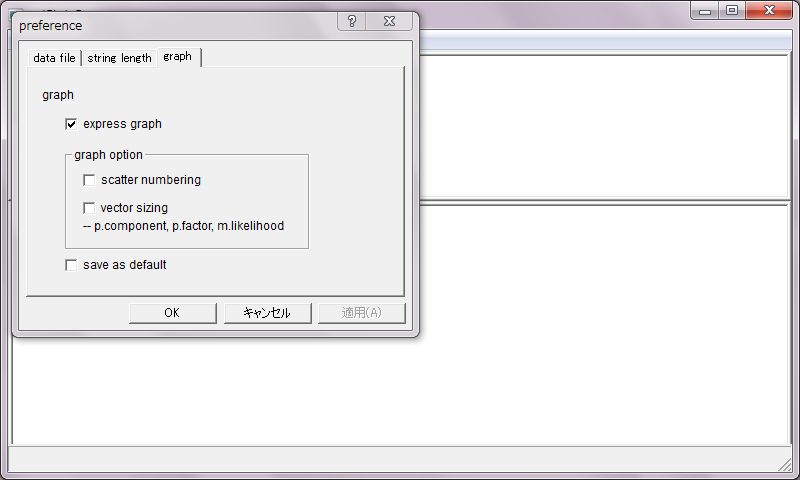
グラフを表示するかどうかを設定出来ます。グラフ表示をする場合に、Principal Component, Principal Factor, Maximum Likelihoodでのマッピングに於いて、ナンバリングと変量ベクトルのサイジングをする事が出来ます
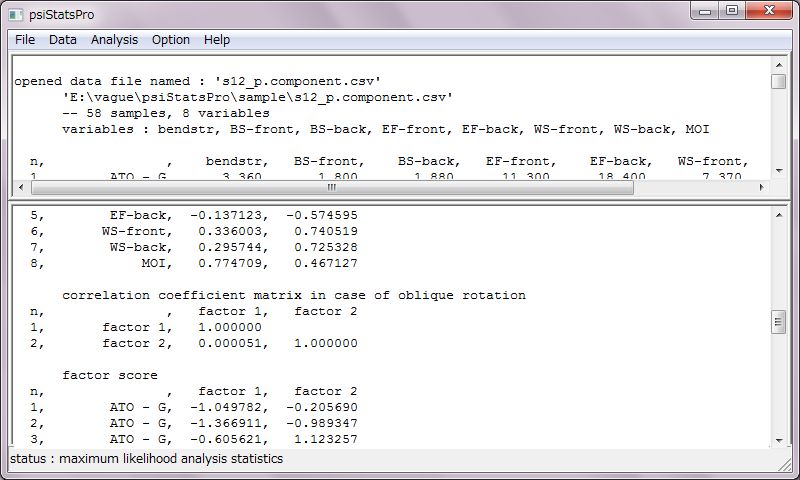
ウィンドウは2つあり、上部スクリーンにデータファイル内容が表示され、下部スクリーンに解析結果が表示されます。メニューから(File/lower Screen/Save As)、表示内容の保存が出来ます。また、スクリーン上で編集する事も出来ます。
| Type |
|
Model |
Method, Option |
| Common Analysis |
|
Fundamental Statistics |
Covariance Matrix, Correlation Coefficients Matrix, Speaman's Ranking Coefficients, Kendall's Ranking Coefficients |
|
|
Multiple Regression Analysis |
All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |
|
|
Principal Component Analysis |
Component Number, Minimum Eigen Value, Correlation Base Matrix, Covariance Base Matrix |
|
|
Canonical Correlation Analysis |
|
|
|
Principal Factor Analysis |
Factor Number, Standardize, SMC, Repetition, Rotation(Oblique/Orthogonal) due to Criterion(Covarimin/Biquartimin/Quartimin, Varimax/Biquartimax/Quartimax) |
|
|
Maximum Likelihood Analysis |
Factor Number, Standardize, SMC, Repetition, Rotation(Oblique/Orthogonal) due to Criterion(Covarimin/Biquartimin/Quartimin, Varimax/Biquartimax/Quartimax) |
|
|
Discriminant Analysis |
Tset Box M, alpha for Canon, F-in Forward Selection, F-in Value, F-in Probability |
|
|
Cluster Analysis |
Division(Sample/Variable), Distance(Mahalanobis/standardized/RawData), Criterion(Nearest Neighbor/Furtherest Neighbor/Median Method/Group Average/Centroid Method/Ward's Method) |
| Quantification Analysis |
|
Association Measures Analysis |
Data Scale(Order Scale/Nominal Scale) |
|
|
Quantification-1 Analysis |
|
|
|
Quantification-2 Analysis |
|
|
|
Quantification-3 Analysis |
Source Data Type(Variable/Cross), Expected Factor Number |
|
|
Three-Way Log linear Analysis |
Source Data Type(Variable/Cross), 1st and 2nd Model test u-term effect, Number of Category A, B, C |
| Similarity Data Analysis |
|
Quantification-4 Analysis |
|
|
|
Principal Co-ordinates Analysis |
Number of Dimention |
| Non-Linear Analysis |
|
Multiple Logistic Model |
Divisional Value, Maximum Iteration |
|
|
Exponential Weibull Model |
Divisional Value, Maximum Iteration |
|
|
Propotional Hazard Model |
Divisional Value, Maximum Iteration |
| Non-Linear Regression Analysis |
|
Convert Degrees of Polynomial Terms |
Degrees, All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |
|
|
Involution Curve Regression Model |
All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |
|
|
Exponential Curve Regression Model |
All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |
|
|
Inverse Curve Regression Model |
All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |
|
|
Logistic Curve 1 Regression Model |
All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |
|
|
Logistic Curve 2 Regression Model |
All Selection, Step Wise(Forward Regression, Forward Selection, Backward Regression, Backward Selection) due to AIC/F-Value, Effective Coverage |